Abstract
- 연속형 Skip-gram 모델이 많은 구문적이고 구분적인 문자 관계를 인식하는 고품질 분포 vector representation을 위한 효율적인 method이다.
- 이 논문은 품질뿐만 아니라 학습 속도를 향상시키는 여러 방법을 소개한다.
- 자주 나오는 단어를 subsampling 함으로서 굉장한 속도 향상과 더 자주 나오는 단어를 학습한다.
- 단어 표현에 있어 내재된 한계점은 단어 순서를 고려하지 않는 점과 숙어 구를 표현하지 못하는 점이다.
1. Introduction
단어들의 분산된 표현의 분산은 비슷한 단어를 묶으면서 알고리즘이 NLP task의 성능을 개선하는 데 도움이 된다.
단어 표현(word representation)은 통계적 언어 모델링과 적용되었고 좋은 성능을 보였다. 후속 작업은 automatic speech recognition, machine translation을 포함한 다양한 NLP task가 있다. skip-gram model은 많은 양의 비구 조적인 텍스트 데이터로부터 고품질의 벡터로 표현된 단어를 학습하는 효율적인 방법이다. word vector를 학습하는 이전의 신경망과 달리 skip-gram model은 dense matrix multiplictaion을 사용하지 않는다. 신경망을 통해 단어 표현을 연산하는 것은 흥미로운데 왜냐하면 학습된 벡터들이 명시적으로 언어적인 규칙성과 패턴들을 encoding 하기 때문이다. 이 논문은 기존의 skip-gram model의 다양하게 확장된 방법들을 소개한다. 학습을 하는 동안 자주 나오는 단어들을 subsampling 하는 것이 지대한 속도 향상과 빈도수가 낮은 단어들을 표현들의 정확도를 높인다. 또한, skip-gram model 학습을 위한 변동성이 단순화된 Noise Contrasive Esimation(NCE)를 소개한다. 이는 계층형 softmax를 사용한 이전의 방법보다 빈도수가 높은 단어들에 대한 더 빠른 학습 속도와 더 나은 벡터 표현을 가능하게 한다. 단어 표현은 개별 단어들의 구성이 아닌 숙어 구를 표현할 수 없는 점에서 한계점을 가진다. 그래서 이런 점이 skip-gram model이 더 인상적인 이유이다. recursive autoencoder와 같은 워드 벡터들을 합쳐서 문장의 의미를 표현하는 다른 기술에도 워드 벡터가 아닌 구절 벡터를 이용하는 것이 도움이 된다. 단어 기반에서 구절 기반으로 확장하는 것은 비교적 단순한다. 우선 data-driven 접근법을 이용하여 많은 양의 구절을 확인하고 이 구절들을 학습 동안 개별 토큰으로 간주한다. 구절 벡터의 품질을 평가하기 위해 저자들은 단어와 구절을 모두 포함한 비슷한 추론을 하는 testset을 개발했다. (paired data를 생성)
2.The Skip-gram model
Skip-gram model의 학습 목표는 문장 혹은 문서 내에서 주변의 단어를 예측하는 데 도움이 되는 단어 표현을 찾는 것이다.
조금 더 자세히 설명하면, 학습 단어 sequence가 주어지면 Skip-gram model의 학습 목표는 average log probability를
최대화하는 것이다.

c는 학습 컨텍스트의 크기이다. 더 큰 c는 더 많은 학습 예시가 되고 따라서 더 높은 정확도를 의미한다.
기본 skip-gram 식은 $p(w_{t+j}|w_t)$ 을 softmax 함수를 이용해 정의한다.

- $v_w$ : $w$의 input vector representation$W$ : vocab안의 단어 수
- $v'_w$ : $w$의 output vector representation
- $W$ : vocabulary의 단어수
2.1 Hierarchical Softmax (계층 softmax)
full softmax의 연산적으로 효율적인 근사는 계층 sofrmax이다
확률분포를 얻기 위해 신경망의 $W$의 출력 노드를 평가하는 것이 아닌 $log_2(W)$ 만 평가하면 되는 것이 큰 이점이다.
2.2 Negative Sampling
hierarchical softmax의 대안으로 노이즈 대조 예측(NCE)가 있다. NCE는 좋은 모델을 로지스틱 회귀를 통해 데이터와 노이즈를 구분한다고 받아들인다.
2.3 Subsampling of Frequent Words
매우 큰 말뭉치에서 가장 자주 등장하는 단어들은 그렇지 않은 단어들과 비교했을 때, 더 적은 정보를 제공한다.

위의 식을 통해 빈도수가 높은 단어의 랭킹은 유지하면서 공격적인 subsampling이 가능하다. 이는 빈도수가 낮은 단어들의 학습을 더 빠르게 하고 정확도를 유의미하게 개선하는 효과가 있었다.
3. Empirical Results
이 섹션에서는 앞서 언급된 Hierachical softmax, Noise Contrasive Estimation(NCE), Negative Sampling, 그리고 subsampling에 대한 평가가 기술되어 있다. 평가는 Analogical reasoning task를 이용했다. Analogical reasoning task는 예를 들어 설명하면 vec(Berlin) -vec(Germany) + vec(France) = vec(x) 일 때 코사인 유사도를 기반으로 x를 찾는다고 생각하면 된다.
4. Learning Phrases
많은 구절이 개별 단어의 뜻의 단순한 의미의 합성이 아닌 의미를 가질 때가 많다. 구절의 벡터 표현을 학습하기 위해서는 함께 문맥에서 같이 등장하는 횟수는 적지만 같이 많이 쓰이는 단어들을 탐색해야 한다. 이렇게 함으로서 많은 양의 합리적인 구절을 단어집의 사이즈를 크게 늘리지 않으면서 구성할 수 있다. 물론 skip-gram을 활용할 수 있겠지만 이는 메모리의 관점에서 효율적이지 못하다.
이를 평가하는 데 있어 이전의 많은 모델이 있어 그것들과 모두 비교하는 것은 연구의 범위에서 다소 벗어나서 조금 더 단순하게 유니 그램과 바이 그램의 등장 수를 이용하여 구절을 구성하는 data-driven approach를 사용한다.

$\delta$는 discounting 계수로 매우 적게 등장하는 단어들로 구성되는 많은 구절을 생성하는 것을 막는데 사용된다.
4.1 Phrase Skip-Gram Results
우선 구절 기반 학습 말뭉치를 만들고 각각 다른 하이퍼 파라미터를 사용하는 skip-gram 모델을 학습했다. 앞과 같이 300 vector dimensionality와 context size는 5였다. 이 설정은 이미 구절 데이터에 대한 좋은 성능을 보였고 이를 통해 빈도수가 높은 토큰의 subsampling이 있을 때와 없을 때의 Negative Sampling과 Hierarchical softmax를 신속하게 비교할 수 있다. 결과는 아래와 같다.

Negative sampling의 k가 5일 때 괜찮은 성능을 보이는데 15일 때 더 나은 성능을 보인다. 놀라운 점은 HS를 subsampling을 하지 않았을 때는 성능이 제일 뒤떨어졌지만, subsampling을 했을 때는 가장 좋은 성능을 보인 것이다.
이는 적어도 몇몇의 경우에서 subsampling은 학습 속도와 정확도를 높이는 데 도움이 된다는 것을 의미한다.
5. Additive Compositionality
이 논문에서 skip-gram 모델로 학습한 단어 표현과 구절 표현은 단순한 벡터 연산을 통해 정확한 analogical resoning을 할 수 있는 선형적 구조를 보인다고 설명했다. 흥미롭게도 skip-gram 표현이 또 다른 선형 구조를 보이는데 이는 벡터 표현의 요소 단위의 덧셈을 통해 단어들의 의미를 결합할 수 있다. 워드 벡터들이 문장에서 주위의 단어들을 예측하도록 학습하면서 단어가 등장하는 문맥의 표현 분포를 나타내는 것으로 보인다.
6. Comparison to Published Word Representation
이전에 나온 다른 신경망 기반의 단어 표현 모델의 결과와 비교했을 때, skip-gram 모델이 가장 뛰어난 성능을 보였다.
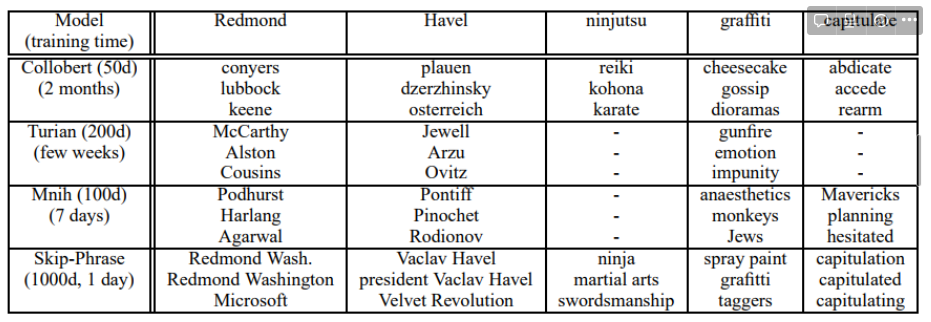
다른 모델로 학습된 벡터의 품질의 차이에 대한 더 많은 인사이트를 위해, 저자는 가장 가까운 빈도수가 낮은 단어들을 보여주면 실험적 비교 결과를 제공한다. 해당 결과는 아래의 표를 참고하면 된다. 이를 자세히 보면 많은 양의 말뭉치를 학습한 큰 skip-gram 모델의 성능이 표현의 질이 더 뛰어난 것을 확인할 수 있다. 이는 이전의 모델 모다 skip-gram 모델이 다른 모델보다 2~3배의 단어인 300억 개의 단어를 학습함으로써 이러한 성능을 이뤄낼 수 있다는 것을 의미한다.
 7. Conclusion
7. Conclusion
이 논문의 주요 기여 포인트는 여러 가지가 있다.
해당 논문에서는 skip-gram 모델을 활용하여 어떻게 분산된 단어 표현과 구절 표현을 학습하는지 보여줬다. 그리고 이러한 표현들이 정밀한 analogical reasoning을 가능하게 하는 선형 구조를 설명했다. 연산적으로 더 효율적인 모델 아키텍처 덕분에 이전에 발표된 다른 모델보다 더 많은 크기의 다른 데이터를 활용하여 모델을 학습했다. 이러한 결과는 단어와 구절 표현의 품질을 크게 향상시키는데 특히 빈도수가 낮은 단어와 구절에 더 효과적이다. 또한 빈도수가 높은 단어들을 subsampling을 하는 것이 학습 속도와 빈도수가 낮은 단어에 대한 정확도를 굉장히 향상시킬 수 있다. 또 다른 기여는 Negative sampling을 통해서 빈번하게 등장하는 단어들에 대한 정확도를 향상시킬 수 있음을 보여준 것이다. 문제마다 다른 최적의 hyperparameter가 있기 때문에 어떤 모델을 채택하고 어떤 hyper parameter를 쓸지는 task에 따라 다르다. 저자들의 경험에 따르면, 모델 아키텍처, vector size, subsampling rate, window의 크기 가 가장 중요한 요소들이라고 소개한다.
흥미로운 것은 단어 벡터들은 단순한 벡터 덧셈이 가능하다는 것이다. 논문에서 제안되는 구절 표현을 학습하는 또 다른 접근법은 그저 단순히 구절을 하나의 토큰으로 표현하는 것이다. 이 두 가지 방법을 결합하면 긴 텍스트 조각을 계산의 복잡성을 최소화하면서 강력하고 단순하게 표현하는 방법이 될 수 있다. 본 논문의 연구를 통해 recursive matrix-vector operation을 통해 표현하고자 하는 현존하는 방법을 보완할 수 있다.
'AI' 카테고리의 다른 글
| [논문리뷰]Generative Adversarial Nets (0) | 2022.09.13 |
|---|---|
| [논문리뷰]Playing Atari with Deep Reinforcement Learning (0) | 2022.09.05 |
| [ML]회귀(Regression) (0) | 2022.05.20 |
| 객체지향 프로그래밍-Object Oriented Programming(OOP) (0) | 2022.04.27 |
| [논문리뷰]StarGAN (0) | 2022.01.18 |




댓글